CMU Researchers Develop Multimodal LLM AI Method Named GILL
Adam KohlhaasThursday, August 10, 2023Print this page.
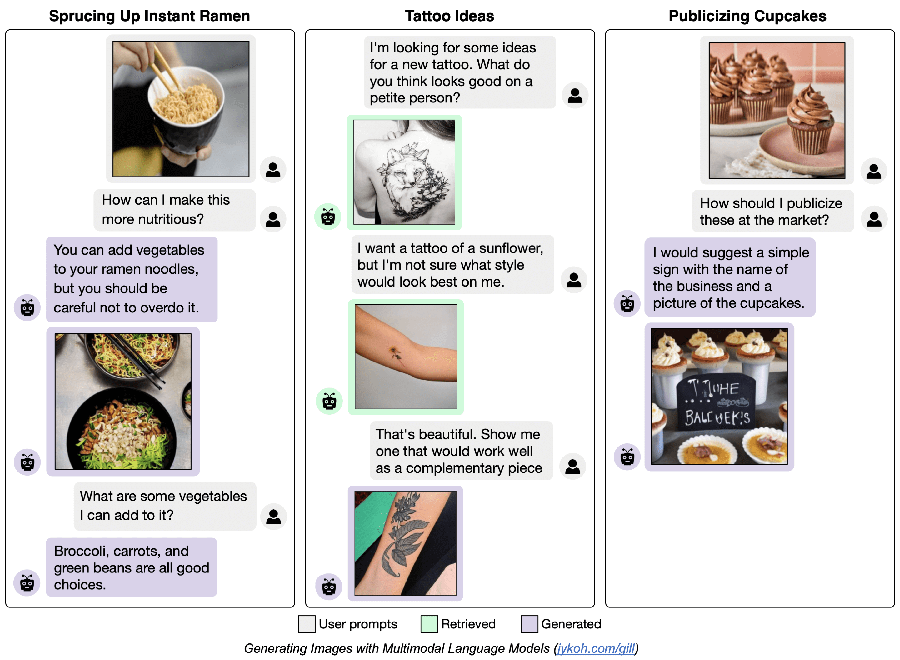
Chatbots like OpenAI's ChatGPT and Google's Bard can achieve impressive results. A human interacting with them uses a specific modality, such as text or an image, to elicit a response. One feature they lack, however, is multimodal integration of text and images for both input and output.
Researchers in Carnegie Mellon University's Machine Learning Department (MLD) and Language Technologies Institute (LTI) have filled this gap by developing a multimodal large language model (LLM) named Generating Images With Large Language Models (GILL). GILL is one of the first models that can process and produce layered images and text, where images and text can be provided as both the inputs and the outputs.
Many existing LLMs accept text and images as input but can't produce images, or can retrieve images but not generate them. GILL accepts both images and text as input and determines the best modality in which to respond. Along with plain text responses, it can also generate images when a more creative answer is needed or an existing image is not available. It can also pull images from an archive in situations requiring a factual response. This flexibility allows the model to seamlessly generate relevant images and layer them with text outputs, producing image and text responses that may be more illustrative than text-only outputs.
"I'm excited about GILL because it is one of the first models that can process image-text inputs to generate text interleaved with retrieved and generated images," said Jing Yu Koh, an MLD Ph.D. student and one of GILL's co-authors. "It is more general than previous multimodal language models and has the potential for a wide set of applications."
GILL's combination of abilities makes it unique among generative AI models. To achieve this combination, the CMU researchers proposed an efficient mapping network to ground the output space of a frozen text-only LLM to the input space of a frozen text-to-image generation model. This action allows the LLM to be efficiently trained to produce vector embeddings compatible with those of the generation model. GILL exhibits a wider range of capabilities compared to prior multimodal language models (such as the ability to generate novel images) and outperforms non-LLM-based generation models across several text-to-image tasks that measure context dependence.
The CMU members involved in this research include Koh; Daniel Fried, an assistant professor in the LTI; and Ruslan Salakhutdinov, a professor in MLD. They're excited about the potential that their method has in future applications.
"GILL is modular, and our approach is model agnostic, meaning that it will likely benefit from applying stronger LLMs and visual models released in the future," Koh said.
For more information about GILL, visit the research project page.
Aaron Aupperlee | 412-268-9068 | aaupperlee@cmu.edu